在当今的互联网时代,亿级用户规模已成为众多头部应用的常态。面对海量的用户请求、行为数据与业务信息,传统单体架构与集中式数据库早已力不从心。如何构建一套高性能、高可用、可扩展的分布式数据存储体系,是每一位从Java后端迈向大数据领域的开发者必须深入思考的核心命题。本文将以王知无在CSDN博客中分享的技术演进为主线,探讨数据处理与存储支持服务在超大规模系统中的设计与实践。
一、 挑战:亿级用户带来的数据存储之困
当用户量突破亿级,数据存储系统面临三重核心挑战:
- 容量挑战:每日产生的结构化、半结构化、非结构化数据可达PB级,传统数据库的纵向扩展(Scale-Up)成本高昂且存在上限。
- 性能挑战:高并发读写(如热点商品秒杀、全民互动活动)要求极低的访问延迟和高吞吐量。
- 可用性与一致性挑战:系统需保障7x24小时不间断服务,并在分布式环境下,于数据一致性(Consistency)、服务可用性(Availability)和分区容错性(Partition Tolerance)之间做出精巧权衡(CAP定理)。
二、 演进:从Java单体到大数据体系的架构升级
王知无在博客中描绘了一条清晰的演进路径:
阶段一:Java单体应用与关系型数据库
早期,业务使用Java EE/Spring框架,搭配MySQL等关系数据库。通过数据库读写分离、分库分表(如使用Sharding-JDBC)缓解压力。这是应对千万级用户的经典方案,其强一致性、事务支持是核心优势,但分片后跨库查询、分布式事务成为痛点。
阶段二:引入分布式缓存与NoSQL
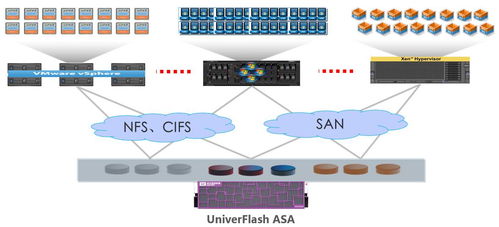
为应对热点数据与高并发读,引入Redis等分布式缓存作为挡板。根据数据特性引入多样化的NoSQL数据库:
- MongoDB/Couchbase:存储灵活的文档型数据(如用户画像)。
- HBase/Cassandra:存储海量的时序数据、日志数据,提供强可扩展性。
- Elasticsearch:用于复杂搜索与聚合分析场景。
此时,架构演变为微服务化,数据存储也进入“多模数据库”时代,技术栈复杂度提升。
阶段三:构建大数据存储与处理平台
当数据真正成为资产,需要被深入分析和挖掘时,大数据平台成为必选项。
- 批量存储与计算:使用Hadoop HDFS作为廉价、可靠的海量数据仓库,通过Hive/Spark进行离线ETL与批处理分析。
- 流式存储与计算:实时数据通过Kafka等消息队列接入,存入Kafka自身(作为持久化缓冲)或流式数据库(如ClickHouse),由Flink/Spark Streaming进行实时处理。
- 数据湖与湖仓一体:为进一步统一数据管理,构建以对象存储(如S3、OSS)或HDFS为基础的数据湖,并利用Delta Lake、Hudi、Iceberg等表格式实现湖仓一体,兼顾灵活性与数仓的管理效能。
三、 核心:数据处理与存储支持服务的设计
在亿级场景下,存储系统不能孤立存在,需要强大的“支持服务”作为粘合剂与赋能层:
- 统一数据访问层(DAL):封装对多种数据库(MySQL, Redis, HBase, ES等)的访问,提供熔断、降级、链路追踪等治理能力,对业务研发透明化数据源的复杂性。
- 数据同步与服务:
- CDC(变更数据捕获)服务:通过Debezium、Canal等工具实时捕获数据库Binlog,将变更数据同步到缓存、搜索或数仓,保障最终一致性。
- 数据复制与备份服务:跨机房、跨地域的数据同步,保障容灾与就近访问。
- 元数据管理与数据治理:建立统一的元数据中心,管理数据的脉络(血缘、影响、schema),实施数据质量监控、生命周期管理(冷热分层,如热数据存SSD/内存,冷数据存HDD/对象存储),这是数据价值得以安全、高效释放的基石。
- 存储资源调度与优化:在Kubernetes等云原生环境中,对StatefulSet(有状态应用)进行自动化部署、扩缩容与存储卷管理,实现存储资源的弹性供给。
四、 实践:选型与平衡的艺术
没有银弹。王知无在博客中多次强调,解决方案的选择是多重因素平衡的结果:
- 数据模型:关系型、键值、文档、宽表、时序还是图?根据业务查询模式决定。
- 读写模式:读多写少、写多读少、点查为主还是范围扫描?这决定了选择LSM-Tree还是B+Tree等底层引擎。
- 一致性要求:强一致、会话一致还是最终一致?不同的业务场景容忍度不同。
- 成本考量:硬件成本、运维复杂度、许可费用都需要纳入评估。
五、 未来展望:云原生与智能化
趋势已然清晰:存储计算分离、容器化编排、Serverless化正在成为新一代分布式存储系统的标配。通过Kubernetes管理有状态数据服务,利用云原生存算分离架构(如Snowflake、Databricks模型)实现极致的弹性与资源利用率。AI for Data Management初露锋芒,未来在智能调参、自动索引、异常预测等方面,AI将为存储系统的自治运维带来革命性变化。
###
从Java开发者到大数据架构师,视角需要从单机性能优化,上升到全局的数据流设计与存储体系规划。亿级用户的分布式数据存储解决方案,是一个融合了经典数据库理论、分布式系统原理、大数据生态工具和持续工程优化的复杂体系。正如王知无所分享的,这条“之路”没有终点,唯有紧跟技术潮流,深入理解业务与数据,才能在数据的惊涛骇浪中,构建出坚固而灵活的诺亚方舟。