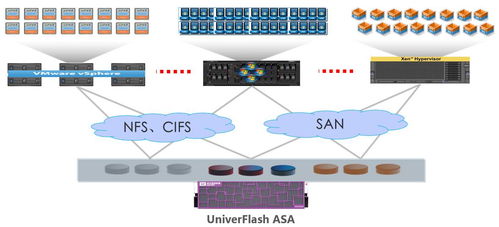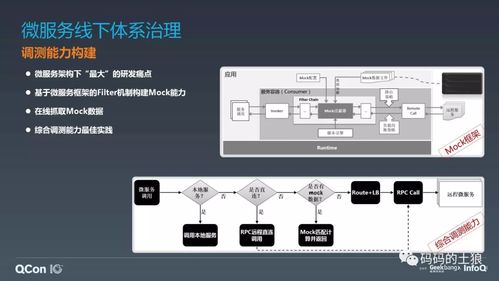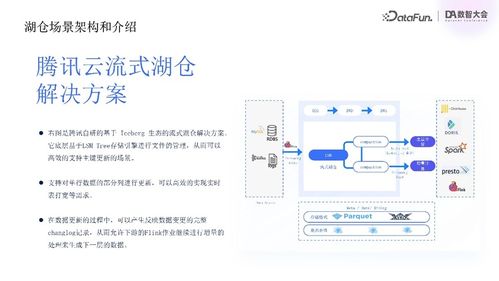
随着数据量爆发式增长和数据实时性要求的提升,传统的数据仓库与数据湖分离架构在成本、复杂度和时效性上面临挑战。腾讯云基于流式计算与存储技术,创新性地提出了流式湖仓统一存储(Streaming Lakehouse)的实践方案,为数据处理和存储支持服务开辟了全新路径,助力企业构建高效、实时、统一的数据底座。
一、 流式湖仓统一存储:架构演进的核心
流式湖仓统一存储并非简单的技术叠加,而是对数据存储、处理与服务模式的深度重构。其核心在于:
- 统一存储层:以对象存储(如腾讯云COS)为基础,构建一个支持海量、多模态数据(结构化、半结构化、非结构化)低成本存储的统一数据湖。
- 流式入湖:摒弃传统的批量T+1数据搬运,通过消息队列(如TDMQ)、数据接入服务(DTS)等,实现业务数据从源头到数据湖的实时、不间断流式写入,确保数据的“新鲜度”。
- 表格式抽象:在原始存储之上,引入Iceberg、Hudi等开源表格式(或腾讯云自研优化格式),为流式到达的原始数据提供数据库般的ACID事务、模式演进、时间旅行等管理能力,构成“湖仓”的关键特性。
- 统一服务层:在此统一的存储与表格式之上,同时支持流处理(Flink)、批处理(Spark)、交互式分析(Presto/Trino)以及AI训练等多种计算引擎的直接分析,实现“一份数据,多种计算”。
二、 数据处理范式的革新
在流式湖仓架构下,数据处理流程被极大简化和加速:
- 实时ETL与CDC:数据库的变更数据(CDC)可实时流式入湖,并基于流处理引擎(如腾讯云Oceanus Flink)在湖内直接进行清洗、转换、打宽,形成可直接服务于分析的实时数仓层。
- 增量处理成为常态:计算任务(无论是分析查询还是模型训练)大部分可基于增量数据展开,避免了全量扫描,资源利用率和处理时效性得到数量级提升。
- 流批一体计算:开发人员可以用同一套流处理API(如Flink SQL)同时处理实时流和湖中的历史批量数据,业务逻辑统一,维护成本降低。
三、 存储支持服务的关键能力
腾讯云在提供底层存储与计算资源的通过一系列托管服务,降低了流式湖仓的构建与运维复杂度:
- 全托管数据入湖服务:提供从各类数据库、日志系统、消息队列到数据湖的一站式、免运维数据实时接入通道,自动处理分库分表合并、格式转换等脏活累活。
- 智能数据管理与优化:
- 自动 compaction:后台自动合并小文件,优化查询性能。
- 数据生命周期管理:基于策略自动将热、温、冷数据分层存储(如从标准COS到归档存储),优化成本。
- 数据治理与元数据管理:提供统一的数据目录、血缘追踪、数据质量监控与敏感数据发现能力。
- 无缝集成的计算引擎服务:提供全托管的流计算Oceanus、弹性MapReduce(EMR)、数据仓库CDW等服务,这些服务开箱即用地支持从统一湖仓中读写数据,用户无需关心底层集成细节。
- 安全与合规保障:在统一存储层集成细粒度的权限控制(如Ranger)、数据加密(服务端/客户端)、网络隔离(VPC)及审计日志,满足企业级安全要求。
四、 实践价值与场景
腾讯云流式湖仓统一存储实践已在泛互联网、金融、零售等行业落地,其价值凸显于:
- 实时数据中台:支撑实时大屏、实时推荐、风控监控等对数据延迟要求秒级甚至毫秒级的场景。
- 一体化数据分析:为BI报表、即席查询、数据科学探索提供一致、最新的数据视图,消除数据孤岛。
- AI工程化:为特征工程和模型训练提供海量、统一且持续更新的数据源,加速AI迭代。
###
腾讯云流式湖仓统一存储实践,通过将流式数据管道、统一低成本存储与现代化表格式深度融合,并辅以强大的托管数据服务,成功构建了面向未来的数据处理与存储支持体系。它不仅解决了数据时效与成本效率的平衡难题,更通过统一的服务接口,让数据能够更流畅、更自由地赋能业务创新,成为企业数字化转型进程中坚实而敏捷的数据基础设施。